Appearance
Table of Contents generated with DocToc
UDP
Message-oriented
UDP is a message-oriented protocol, and message means chunks of data that are delivered on the internet. UDP only delivers the message, without any handling like split or combine.
More specifically:
- At the sender's end,when a UDP message is sent, the UDP protocol will get the data from the application layer, and it will only add the UDP header to the data, nothing else, then deliver it to the network layer.
- At the receiver's end,when getting a UDP message from the network layer, the UDP protocol will only remove the additional IP header on data without any other operations.
Unreliable
- UDP is connectionless, communication happens without connecting or disconnecting;
- UDP is unreliable, it will deliver whatever it has got, no cache is involved and it does not care about the delivery.
- UDP has no congestion control, data is sent at a constant speed. Even if the network is terrible, it will not adjust the speed, so it is inevitable to lose some packets. However it has the advantage of real-time applications, for example we will use UDP instead of TCP in telephone conference.
Efficient
Since there is no guarantee of delivery and no promise that data is not lost and arrives in orderly in UDP, it is not as complicated as TCP. It does not cost a lot in its header data with only 8 bytes, much less than TCP whose head data needs at least 20 bytes. So it can transport data efficiently.

The UDP header consists of 4 fields:
- two port number of 16 bits, source port (optional) and destination port
- the length of the data
- checksum (IPv4 optional) which is used for error-checking of the header and the data.
Transmission mode
The transmission modes of UDP contains not only one-to-one, but also one-to-many, many-to-many, and many-to-one, which means UDP supports unicast, multicast and broadcast.
TCP
Header
The header of TCP is much more complicated than UDP's:
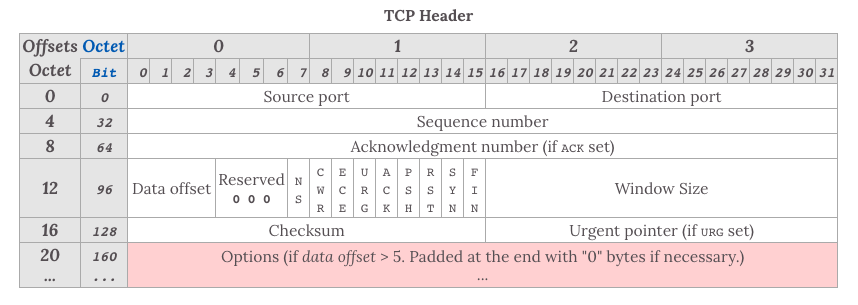
When talking about the header of TCP, these fields are significant:
- Sequence Number: This number can guarantee that all the segments are ordered, and the opposite host can order the segments by it.
- Acknowledgment Number: This number indicates the next segment number that the opposite host expects, and everything before this has been received.
- Window Size: How many segments can the opposite host accept; it is used to control the flow.
- Identifier
- URG=1: When this flag is set, that means this segment is urgent and should be prioritised.
- ACK=1: Besides according to the TCP protocol, after connection, all the segments that transported should set the ACK=1.
- PSH=1: When this flag is set, it means that the receiver should push the data to the application layer instead of store it in the caches until the cache is full.
- RST=1: When this flag is set, it means that the TCP connection has a serious problem. It may need to reconnect. It also can be used to refuse invalid segments or requests.
- SYN=1: When SYN is 1 and ACK is 0, it means that this is a connect request segment, while SYC is 1 and ACK is 1, it is a response that agrees to connect.
- FIN=1: When this flag is set, it means that this is a request segment that asks for closing the connection.
State machine
HTTP is stateless, so TCP which is under the HTTP is also stateless. It seems like that TCP links two ends, client and server, but it is actually that both these two ends maintain the state together: 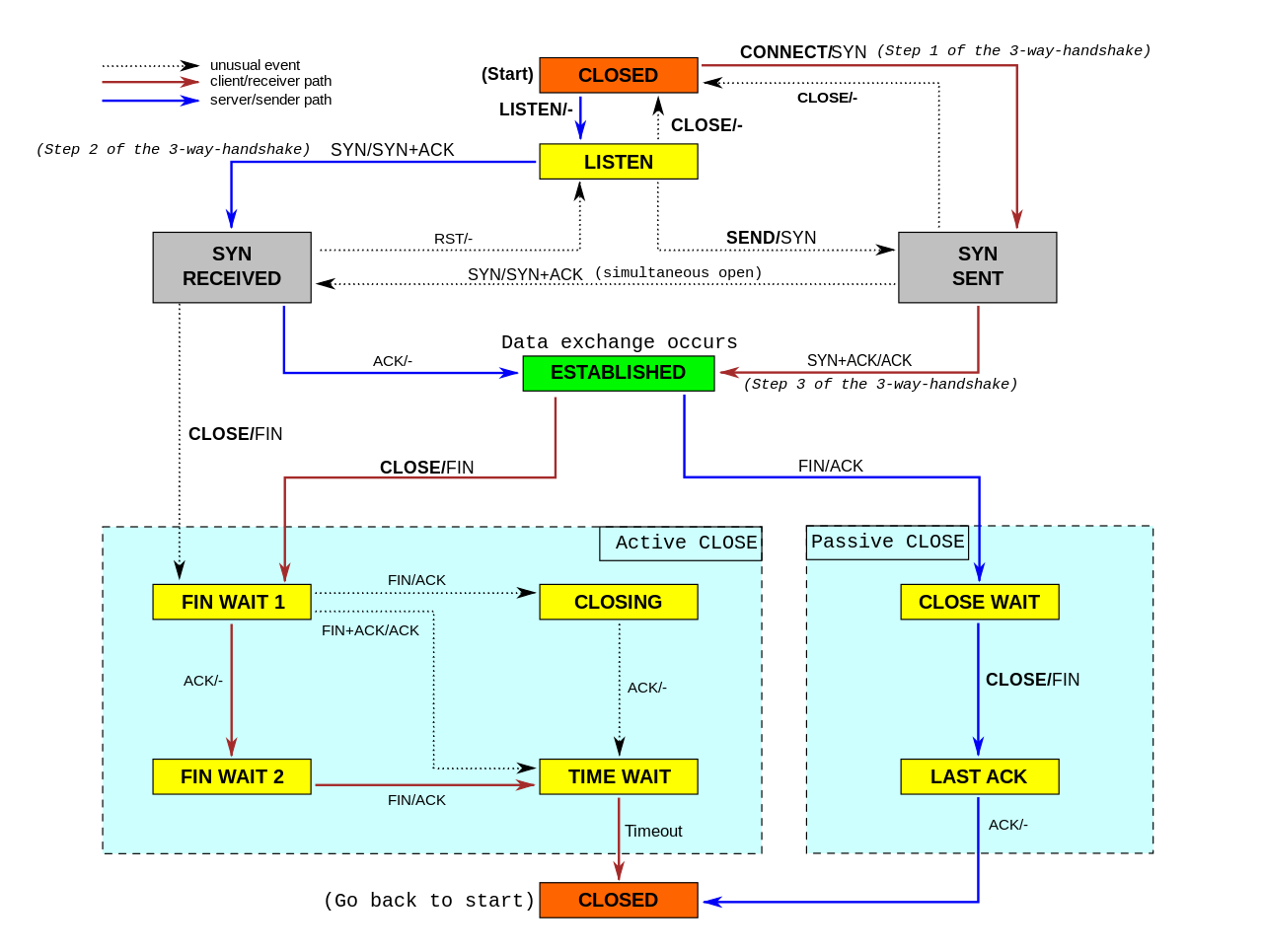
The state machine of TCP is very complicated, and it is closely related to the handshake of opening and closing a connection. Now we'll talk something about these two kinds of handshake. Before that, you'd better know something about RTT(Round-Trip-Time), an important index of performance. It is the time it takes for a signal to be sent plus the time it takes for an acknowledgement of that signal to be received.
Three-way handshake in opening a connection
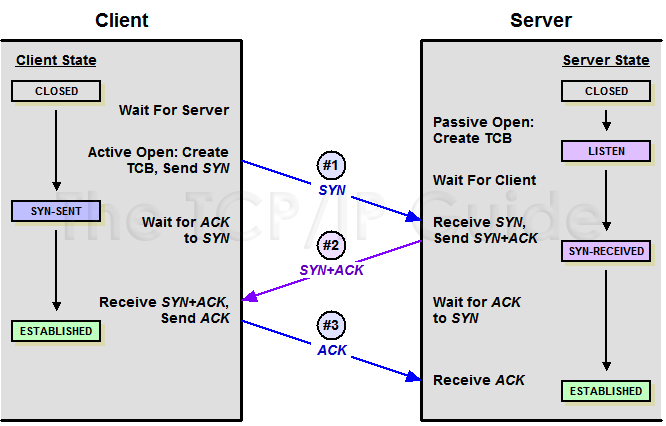
In TCP, the end which is active open is called the client and the passive open is called the server. No matter client or server can send and receive data after connection, so TCP is a bi-directional communication protocol. At first, both ends are closed. Before communication, both of the ends will create the TCB(TCP Control Block). After that, the server will be in the LISTEN state and begin to wait for the data from the client.
First handshake
The client sends a connect request which contains an SYN. After that, the client is in the status called SYN-SENT.
Second handshake
After getting the request, the server will send a response if it agrees to establish a connect and then turn to SYN_RECEIVED. There is also an SYN in the response.
Third handshake
When the client receives the agreement of establishing a connection, it needs to send an acknowledgement. After that the client turns to ESTABLISHED, and the server turns to the same state after receiving the acknowledgement. The connection is established successfully by now.
PS: In the process of the third handshake, it is possible to carry data in it by using TFO. All protocols about handshake can use methods of TFO-like to reduce RTT by storing the same cookie.
Why need the third handshake if the connection can be established after the first two?
This will prevent the scenario that an invalid request reaches the server and results in wasting server's resource.
Imagine that, the client sends a connect request called A, but the network is bad so client retransmits another called B. When B reaches the server, the server handles it correctly, and the connection will be established successfully. If A reaches when connect B is closed, the server might think that this is a new request. So the server handles it and enters ESTABLISHED state while the client is closed. This will waste the resource of the server.
PS: Through connecting, if any end is offline, it needs to retransmit, generally, five times. You can limit the times of retransmitting or reject the request if can't handle it.
Four-handshake of disconnect
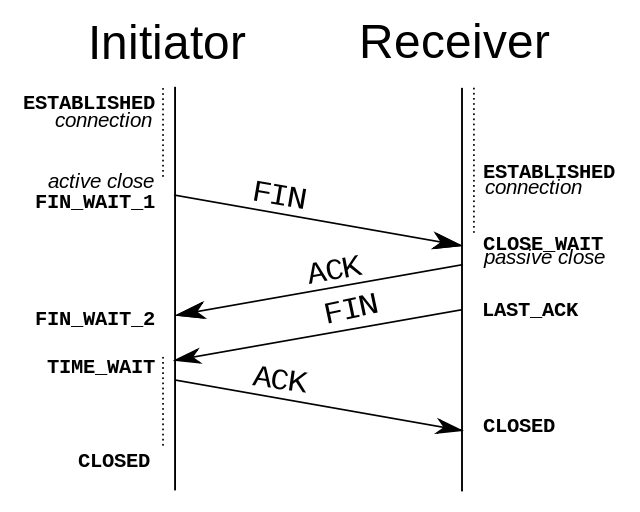
TCP is a bi-directional communication protocol, so both ends need to send FIN and ACK when closing a connection.
First handshake
Client A asks the server B to close a connection if it thinks there is no data to send.
Second handshake
After receiving the request, B will ask the application layer to release the connection and send an ACK, then enter CLOSE_WAIT state. That means the connection from A to B has been terminated and B will not handle the data from A. But B still can send data to A because of bi-direction.
Third handshake
B will continue to sending data if needed, after that it will ask client A to release the connection and enter LAST-ACK state.
PS: The second and the third handshake can be combined by delay-ACK. But the delay time should be limited. Otherwise, it will be treated as a retransmission.
Forth handshake
A will send the ACK response and enter TIME-WAIT state after receiving the request. The state will last for 2MLS. MLS means the biggest lifetime that segment can survive and it will be abandoned if beyond that. A will enter CLOSED state if there is no retransmission from B among 2MLS. B will enter CLOSED state after receiving the ACK.
why A should enter TIME-WAIT state for 2MSL before it enters CLOSED state
This can ensure that B is enabled to get the ACK from A. If A enters CLOSED state immediately, B may be not able to close correctly for not receiving the ACK with bad network.
ARQ protocol
ARQ, also known as automatic repeat request, is an error-control method for data transmission that uses acknowledgement and timeouts. It includes Stop-and-Wait ARQ and Continuous ARQ.
Stop-and-Wait ARQ
Normal transport
As soon as A sends a message to B, it has to launch a timer and wait for a response, then cancels the timer and sends another message after receiving the response.
Packet lost or error
It is possible to lose packet in transmitting. So it needs to retransmit the message if the timer reaches time-out before receiving the response. That is why we need a data copy.
There also might be problems in transmitting even if the server receives the message correctly. If so the message will be discarded, and the receiver waits for another transmission.
PS: Generally, the limit set by the timer is longer than the average of RTT.
ACK time-out or lost
The response of B may also have the problem of packet loss or time-out. In this case, the client needs to retransmit. When the server gets the same SYN flag, it will discard the message and send the previous response until receiving the next SYN.
The response may arrive after the time limit, and client A will check whether it gets the same ACK, if true, discards it.
The client has to wait for the ACK even in good network, so the transmission efficiency is terrible, and that is the shortcomings of this protocol.
Continuous ARQ
The sender has a sending window in which all the data will be sent without the ACK in Continuous ARQ. This can improve efficiency by reducing the waiting time comparing to the Stop-and-Wait ARQ.
Cumulative Acknowledgement
The receiver will receive messages nonstop in Continuous ARQ. If it sends a response immediately every time like Stop-and-Wait ARQ, it may waste the resource too much. So client B can send an ACK after receiving a number of messages, that is called Cumulative Acknowledgement. The ACK indicates that all the data before this flag had been received and client A should send the next message.
But there is also a culprit. Imagine that client A sends a number of messages from segment 5 to segment 10 in Continuous ARQ, and client B receives all the segments successfully except segment 6. In this case, client B has to send the ACK of 6 even though the segments after 6 had been received successfully which causes performance issues. In fact, this problem can be solved by Stack which will be mentioned later.
Sliding window
We have mentioned the sliding window above. In TCP both ends maintain the windows, send window & receive window respectively.
The send window contains data that has been sent but not received, and data that can be sent but not sent yet:
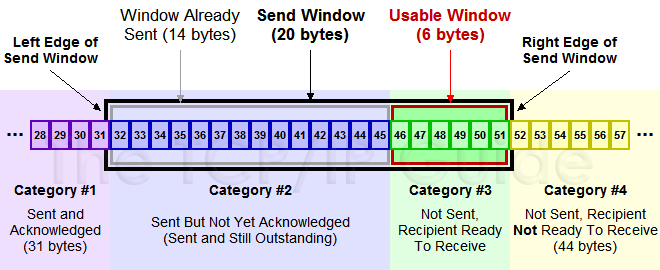
The size of the send window is determined by the size of the remaining receive window. The response will carry the size of current remaining receive window, and when sender receives the response, it will set the size of the send window by response value and network congestion. So the size of the send window is changeable.
When sender receives the response, it will slide the window accordingly:
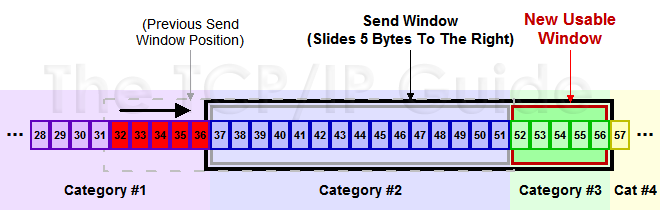
Sliding window implements flow control. The receiver notifies the sender of the data size which can be handled to ensure itself can handle all data successfully.
Zero window
There may be a zero window on the opposite end through the transmission. In this case, the sender will stop sending data and launch a persistent timer which can send a request to the receiver to ask for the window size. After trying several times, it may terminate the TCP connection.
Congestion Control
Congestion control is different from flow control. The latter is used in the receiver to ensure that it can handle all data in time. The former is used in the network to avoid network congestion or network overload.
There are four algorithms in congestion control: Slow-start, Congestion Avoidance, Fast Retransmit and Fast Recovery.
Slow-start algorithms
As the name suggests, it is to exponentially expand the send window at the beginning of the transmission, thereby avoiding network congestion caused by transmission of large amounts of data from the start.
Steps of Slow-start are as follows:
- set the congestion windows size of 1 MSS at the beginning of the connection.
- double the size after each RTT
- when the size reaches the threshold, the Congestion Avoidance algorithms begins.
Congestion Avoidance algorithms
It is simpler than Slow-start. One each RTT it will only increase the size of the congestion window by one. By this way, it can avoid network congestion caused by exponentially increasing of window size and slowly adjusts the size to optimal value.
TCP will treat it as network congestion when timeout is reached in transmitting. It will do the follows immediately:
- reduce the current threshold of the congestion window to half
- set the value of the congestion window to 1 MSS
- start the Congestion Avoidance algorithms
Fast Retransmit
Fast Retransmit always appears with Fast Recovery. Once the data got by the receiver is disordered, the receiver will only send a response with the last correct SYN (without the Sack). If the sender gets three repeated ACK, it would start fast retransmit immediately instead of waiting for the timeout.
The realization of TCP Taho
- reduce the current threshold of the congestion window to half
- set the value of the congestion window to 1 MSS
- re-start the Slow-start
The realization of TCP Reno
- reduce the congestion window to half
- set the threshold same as the size of the current congestion window
- enter the stage of Fast Recovery (retransmit the packet, leave this stage once gets a new ACK)
- use Congestion Avoidance algorithms
Fast Recovery (TCP New Reno)
TCP New Reno improves the previous TCP Reno. Before this, it will drop out once gets a new ACK.
TCP sender will store the biggest queue number of three repeated ACK in TCP New Reno.
If a segment carries the message from number 1 to 10 but the data of 3 and 7 is lost, the biggest number in this segment is 10. The sender will only get the ACK of 3. Then the data of 3 will be retransmitted, and the receiver receives it and sends the ACK of 7. At this time, TCP knows that the receiver loses more than one packets and will continue to send the data of 7. The receiver receives it and sends the ACK of 11. By now, the sender infers that the segment has been received successfully and will drop out the stage of Fast Recovery.
HTTP
HTTP protocol is stateless, it does not store any status.
Difference between POST & GET
First we'll introduce the concept of idempotence and side-effects.
Side-effects mean that operations can cause a change in state on the server. Searching for some resource has no side-effects but registering does.
Idempotence means that the side-effects of N > 0 identical requests is the same as for M > 0 identical requests. Registering 10 accounts are the same as 11 accounts, while changing an article 10 times is different from 11 times.
Generally, Get is usually used in idempotent scenarios which have no side-effects while Post is used in none-idempotent scenes which have side-effects.
Technically speaking:
- Get could cache the response but Post could not
- Post is safer than Get, because the params of Get is included in URL and the browser will cache the resource, while post keeps params in the request body. But Post data also can be captured with tools.
- Post can transport more data in
request body, while GET can't. - Since the URL length is restricted, data transported by Get is restricted, and the limit varies by browser. But with Post, data is in the request body, so there is no limit on length.
- Post supports more encoding types and does not impose limitation on the data type.
Common Status Code
2XX success
- 200 OK: The request from the client has been handled correctly in the server.
- 204 No content: The server successfully processes the request and is not returning any content.
- 205 Reset Content: The server successfully processes the request, but is not returning any content. Unlike a 204 response, this response requires that the requester reset the document view.
- 206 Partial Content: The server is delivering only part of the resource (byte serving) due to a range header sent by the client.
3XX Redirection
- 301 Moved Permanently: The resource has been moved to a new URI permanently. This and all future requests should be redirected to the given URI.
- 302 Found: The resource has been moved to a new URI temporary. This request should be redirected to the given new URI.
- 303 See other: The response to the request can be found under another URI in the response using GET method.
- 304 Not Modified: It indicates that the resource has not been modified since the version specified by the request headers If-Modified-Since or If-None-Match. In such case, there is no need to retransmit the resource since the client has a previously download copy.
- 307 Temporary Redirect: In this case, the request will re-redirected to a new URL for temporary, and future requests should still use the origin URI.
4XX Client Errors
- 400 Bad Request: The server will not or can not process the request due to an apparent client error.
- 401 Unauthorized: When the authentication of the request is required and has failed or has not yet been provided.
- 403 Forbidden: The request is valid, but the server is refusing action. The user might not have the necessary permission for a resource or may need an account of some sort.
- 404 Not Found: The requested resource could not be found in the server but may be available in the future.
5XX Server Errors
- 500 Internal Server Error: The server encounters an error when processing the request.
- 501 Not Implemented: The server cannot fulfil the request.
- 503 Service Unavailable: The server is currently unavailable because it is overloaded or down for maintenance.
Common Fields
| Common Fields | Description |
|---|---|
| Cache-Control | it tells caching mechanisms |
| Connection | type of connection that the browser prefers, e.g. keep-alive |
| Date | the date and time that the message was sent |
| Pragma | message directives that may have various effects anywhere along the request-response chain |
| Via | informs the client of proxies through which the response was sent |
| Transfer-Encoding | the form of encoding used to safely transfer the entity to the user |
| Upgrade | asks the opposite domain to upgrade another protocol |
| Warning | a general warning about problems with the entity body |
| Request Fields | Description |
|---|---|
| Accept | media types that are acceptable for the response |
| Accept-Charset | character sets that are acceptable |
| Accept-Encoding | list of the acceptable encodings |
| Accept-Language | list of the acceptable languages |
| Expect | indicates that particular server behaviors are required by the client |
| From | the email address of the user making the request |
| Host | the domain name of the server and the TCP port number on which the server is listening |
| If-Match | if the client supplied entity matches the same entity on the server, the request will be performed |
| If-Modified-Since | allows a 304 Not Modified to return if the content is unchanged(compare with the Date) |
| If-None-Match | allows a 304 Not Modified to return if the content is unchanged(compare with the ETag) |
| User-Agent | the user agent string of the user agent |
| Max-Forwards | limit the number of times the message can be forwarded through the proxies and the gateways |
| Proxy-Authorization | authorization credentials for connecting a proxy |
| Range | request only part of an entity, bytes are numbered from 0 |
| Referrer | this is the address of the previous web page from which a link to the currently requested page was followed |
| TE | the transfer encoding that user agent is willing to accept. The same values as for the response header field Transfer-Encoding can be used |
| Response Fields | Description |
|---|---|
| Accept-Ranges | what particle content range types this server supports via type serving |
| Age | the age the object has been in a proxy cache in seconds |
| ETag | an identifier for a specific version of a resource, often a message digest |
| Location | used to redirect to a new URL |
| Proxy-Authenticate | request authorization to access the proxy |
| Server | name of the server |
| WWW-Authenticate | indicates the authorization scheme that should be used to access the requested entity |
| Entity Fields | Description |
|---|---|
| Allow | valid methods for a specified resource |
| Content-Encoding | the type of the encoding used on the data |
| Content-Language | the language used on the content |
| Content-Length | the length of the response body |
| Content-Location | an alternate location for the returned data |
| Content-MD5 | a Base64-encoded binary MD5 sum of the content of the response |
| Content-Range | wherein a full body massage this partial message belongs |
| Content-Type | the MIME type of the content |
| Expires | the date after which the response is considered stale |
| Last_modified | the last modified date of the requested object |
PS: Another chapter on cache can be found in here.
HTTPS
HTTPS transfers data by HTTP and data is encrypted by TLS protocol.
TLS
TLS protocol is above the transmission layer and below the application layer. The first time to use TLS to transfer data need RTT twice, and then we can reduce it to once by using Session Resumption.
There are two techniques for encrypting information: symmetric encryption and asymmetric encryption.
symmetric encryption
A secret key, which can be a number, a word, or just a string of random letters, and is recognized by both sender and recipient, is applied to encrypt and decrypt all the messages.
asymmetric encryption
There are two related keys -- a key pair -- in the asymmetric encryption. A public key is made freely available to everyone. A second, private key is kept the secret so that only you know it. The private key can only decrypt the message encrypted by the public key.
TLS handshake
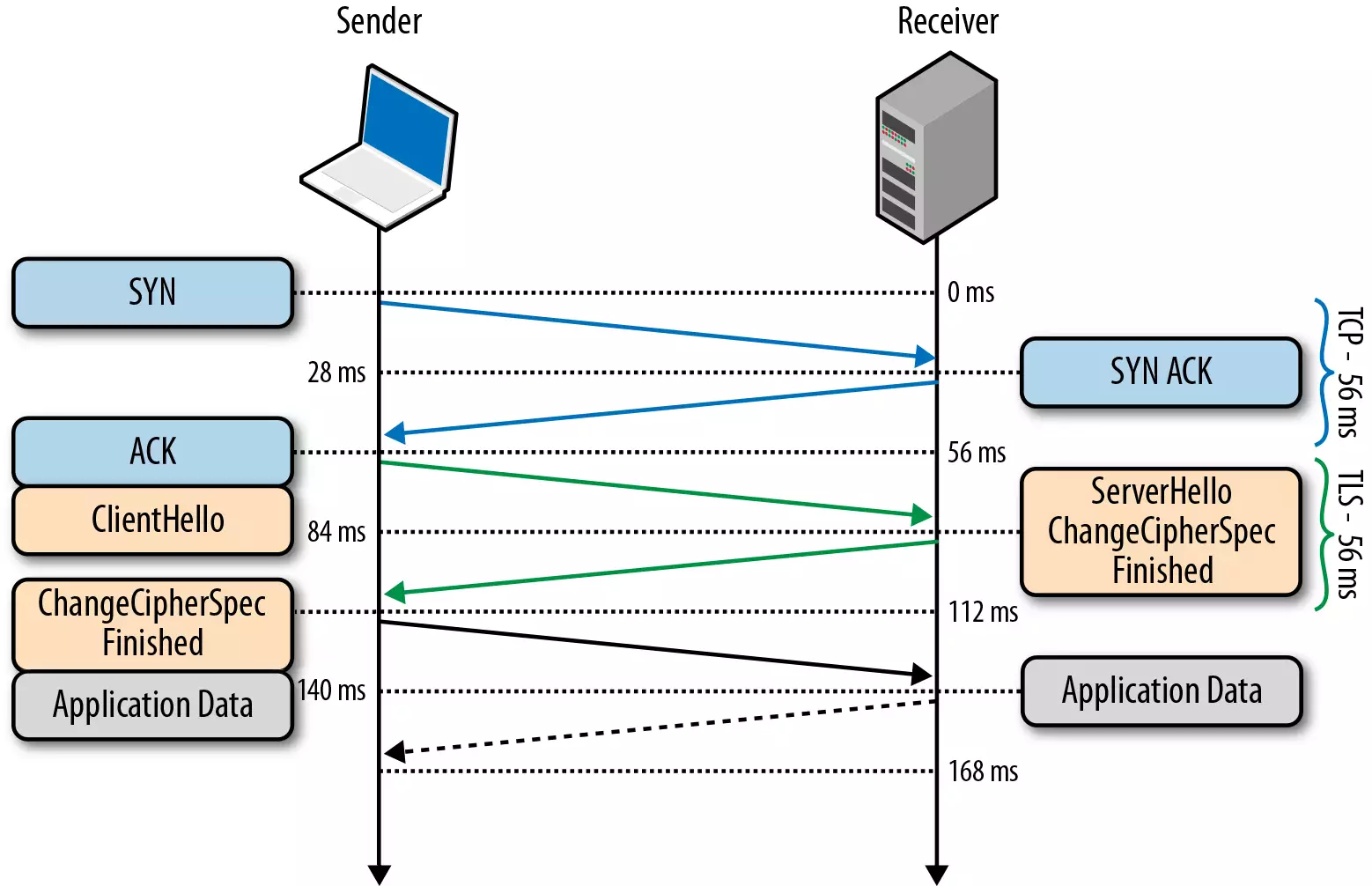
- Client: Sends a "hello" to the server along with a random value and supported cipher suites.
- Server: Responds back by saying "hello" with it's own generated random value and its certificate.
- Client: Verifies the certificate. Creates a Pre-Master Shared (secret) key and encrypts it using the public key from the server Certificate and sends it to the server.
- Server: Recieves the Pre-Master Shared secret key and decrypts using its private key. Both the server and client generate a master key & sessions key based on the Pre-Master Shared (secret) Key.
- Client: Sends a message to the Server to inform that it will be changing cipher spec and will use the sessions key for hashing and encrypting the messages.
- Server: Changes its cipher spec and switches to symmetric encryption using the sessions key for performance.
Gives the above steps, during the handshake process, the client and server communicate with asymmetric encryption. And later switch to symmetric encryption, once the connection is established for better performance.
PS: The above description is the handshake of TLS 1.2 protocol. In 1.3 protocol, only one RTT is needed to establish a connection for the first time, and the RTT is not required to restore the connection later.
HTTP/2
Compare with HTTP/1.X, there is a substantial increase in the web's performance with HTTP/2.
We usually use CSS Sprite, base64, multiple-domain-names and so on to improve the performance. It is all because browser limits the number of HTTP connections with the same domain. If there are too many resources to download, all these resources need to be queued. And if limit is hit, those over the limit will need to wait until previous ones have been completed. That is called head-of-line blocking.
You can see how much faster of HTTP/2 than HTTP/1.x by this link:

You will find the request queue is something like this in HTTP 1.x because of head-of-line blocking:
But with the MultiPlexing in HTTP/2, you'll find this:
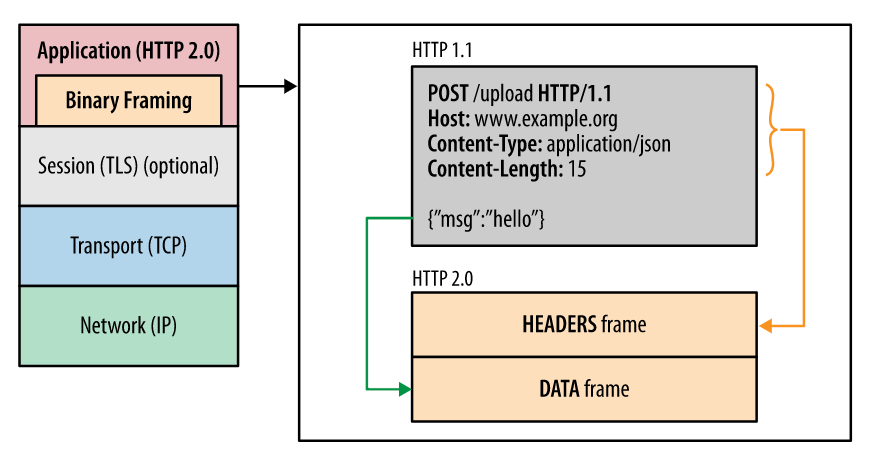
Binary Transport
This is the point of all the improvement of performance in HTTP/2. We transfer data by plain text in the previous versions of HTTP. But in HTTP/2, all of the data transferred will be split and transported by binary with the new encoding.
MultiPlexing
There are two important concepts in HTTP/2: frame and stream.
- Stream: A bi-directional flow of bytes within an established connection, which may carry one or more message.
- Frame: The smallest unit of communication in HTTP/2, each containing a frame header, which at a minimum identifies the stream to which the frame belongs.
There is one or more stream in a single connection, so we can send more than one request, and the opposite end can identifies which the request belongs to by the identifiers in the frame. By this, we can avoid the head-in-line blocking and greatly improve the performance.

Header compression
In HTTP/1.X, we transfer data of the header by plain text. In the case where the header carries a cookie, it may be necessary to transfer hundreds to thousands of bytes each time repeatedly.
In HTTP 2.0, the header of the transport is encoded using the HPACK compression format, reducing the size of the header. The index table is maintained at both ends to record the occurrence of the header. The key name of the already recorded header can be transmitted during the transmission. After receiving the data, the corresponding value can be found by the key.
Server push
In HTTP/2, the server can actively push other resources after a request from the client.
Imagine that, something in the server is necessary to the client, so the server can push the associated resources ahead of time to reduce the delay time. By the way, we can also use pre-fetch if the client is compatible.
QUIC
QUIC (Quick UDP Internet Connections) that designed by Google is a transport layer network protocol based on UDP. QUIC's main goal is to improve the performance of connection-oriented web applications that are currently using TCP.
- HTTP/2 is based on TCP and because of the retransmission mechanism of TCP, head-of-line blocking will occur even if only one packet fails. QUIC is based on UDP and supports multiplexing thus has no such problem.
- It implements its own encryption protocol, and can achieve 0-RTT through TCP-like TFO mechanism. Of course TLS 1.3 has already achieved 0-RTT too.
- It has retransmission support and forward error correction. If you only lose one packet, and you don't have to retransmit, you can use forward error correction to resume the lost packet.
- QUIC can use forward error correction to reconstruct lost packets with scheme similar to RAID systems using XOR operations.
- But it cannot reconstruct lost packets when multiple packets are lost within a group.
DNS
The Domain Name System (DNS) matches the IP address by given hostname.
The IP address which is composed of a number and letter is difficult for human to remember, so the hostname is created. You can treat the hostname as the alias of the IP address. The DNS is used to convert a hostname to its real name.
The process of DNS begins before TCP handshake, and it is processed by the operating system. When you type www.google.com in the browser:
- the OS queries from the local cache first;
- query to the configured DNS servers by OS if there is no result in step1;
- query to the DNS root server, which can offer a server who can resolve all the top level domains such as
.com; - then query to the server specified by step3 and look up the second-level domain name
google; - the third level domain name like
wwwis configured by yourself. You can setwwwto an IP address, and do the same thing to another third level domain.
The above is called DNS Iterative Query, there is another way to query DNS: Recursive Query. The difference between them is that the former do the query by the client while the latter does by the configured DNS servers and then transport the received data to the client.
PS: DNS query is based on UDP.
What happens when you navigate to an URL
This is a classical question in an interview. We can concatenate the topics all above in this theme:
- Do the DNS query first, it will offer the most suitable IP address with the intelligent DNS parsing.
- The following is the TCP handshake. The application layer will deliver the data to the transport layer where the TCP protocols will point out the ports of both ends, and then transport the data to the network layer. The IP protocols in the network layer will determine the IP address and how to navigate to the router, and then the packet will be packaged to data frames. And at last is the physical transport.
- After the TCP handshake is the TLS handshake, and then is the formal data transport.
- It is possible for the data to go through the load balancing servers before its accesses to the server. The load balancing server will deliver the requests to the application servers and response with an HTML file.
- After getting the response, the browser will check the status code, it will continue parsing the file with the status code 200. As for 400 or 500, it will throw an error. If there is 300 code, it will redirect to a new URL. And there is also a redirection counter to avoiding too much redirection by throwing an error.
- The browser will parse the file, do decompression if the file type is with compressions like gzip and then parse the file by the encoding type.
- After the successful parsing, the render flow will start formally. It will construct the DOM tree by HTML and construct the CSSOM with CSS. If there is a
scripttag, browser will check it whether has theasyncordeferattributes, the former will download and execute the JS file in parallel, and the latter will load the file first then wait to execute until the HTML has been parsed. If none of them, it will block the render engine until the JS file has been executed. HTTP/2 may highly improve the download efficiency for pictures. - The
DOMContentLoadedevent will be triggered after the initial HTML has been loaded and parsed completely. - The Render tree will be constructed following the CSSOM and the DOM tree, in which the layout of page elements, styles and so on will be calculated.
- In the process of constructing the Render tree, the browser will call the GPU to paint, composite the layers and display the contents on the screen.